When the rollback gets cheap.
A new jailbreak family lands in production at 11pm Friday. Today the patch cycle is measured in weeks. We think it should be measured in seconds — and the property that closes the gap isn’t the patch, it’s the rollback. A note on what jailbreak defense looks like when the install is sub-minute, the removal is bit-identical, and the slot stays dormant on every benign query.
A new jailbreak family lands in production at 11pm on a Friday. The team on call has watched four versions of the same attack pattern come through the logs in the last hour. They have pulled a couple of representative examples. The next decision is whether to ship a fix tonight or to wait until Monday. The question that decides it is the one that gets asked least often in public and most often inside production AI groups: what’s the timeline for a fix that doesn’t break benign users?
§ The Friday-night question.
The shelf of available answers, today, is not encouraging. Reinforcement learning from human feedback — months. Constitutional AI training — months. A targeted safety fine-tune on a LoRA adapter — hours, plus a regression pass against the rest of the eval suite, plus a checkpoint push to the inference fleet. A system-prompt patch — seconds, but easily defeated by the next attacker variant, and a tax on every single user request that has nothing to do with the attack.
Each of these is a reasonable answer to a slightly different question. None of them is a good answer to the one the on-call team has at 11pm on a Friday — because none of them combine four properties at once. Sub-minute deployment. Bit-identical removal. Per-attack selectivity. Effectiveness in the same band as multi-month alignment work. The gap between any single defense and that combined target is the substance of the work in this note.
§ The four properties.
Take each property in turn. Sub-minute deployment is mostly an operations claim — the cost of the install is small enough that it can be made under pressure and re-made if it doesn’t land cleanly. Bit-identical removal is the property that makes the install tolerable; if the patch causes a regression nobody saw coming, the model can be returned to the state it was in five minutes ago, exactly. Per-attack selectivity is what makes the install invisible to benign users — the patch fires only on inputs that match the targeted threat pattern, and on the rest of the traffic the model behaves as it did the day before. Effectiveness in the alignment band is what makes any of the other three worth caring about; a fast, reversible, selective patch that doesn’t actually stop the attack is just theater.
The four properties don’t sit comfortably together in any defense already on the shelf. RLHF and Constitutional AI hit the effectiveness property well; they fail the deployment-time property by months and the reversibility property by what amounts to a checkpoint rollback. Safety fine-tunes hit reversibility partially and effectiveness well, but live at the wrong end of the deployment-time scale. System prompts hit deployment time at seconds but fail effectiveness, fail selectivity (every user pays a context-window tax), and fail effectiveness under attacker iteration particularly hard. The empty quadrant has the same shape as the one in the previous note in this series — a quadrant nobody was serving.
What we have learned over the last eight months is that the empty quadrant has a shape, and that the shape is buildable.
§ What the slot does, at the behavior level.
DeltaWrite is the system the lab built around bounded persistent inference-time adaptation. The version of it described in the previous note was scoped at teaching a frozen language model one more thing. The version described here is scoped at defending a frozen language model from a class of input it shouldn’t comply with. The mechanism is the same; the application sits at the other end of it.
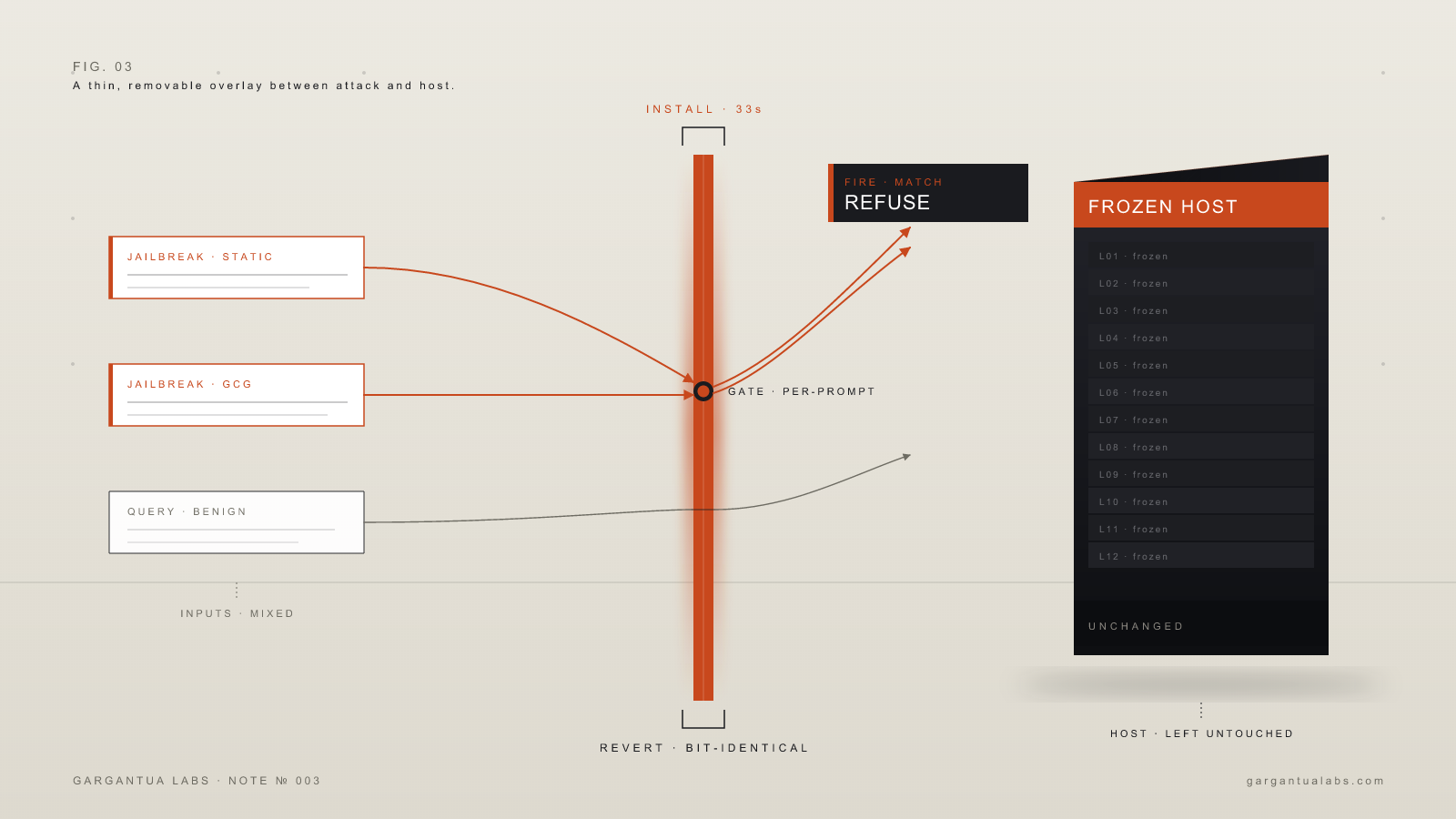
A defensive deployment, at the behavior level, is two pieces. The first is a compact runtime modification to the host that biases the model’s output toward a clean refusal when the modification is active. The second is a small selective gate — a classifier of the kind a competent ML engineer could build on a Tuesday afternoon — that decides per-prompt whether the modification should be active. On inputs that match the targeted threat pattern, the gate fires, the modification engages for the lifetime of that one generation, and the model produces the refusal. On every other input, the gate stays quiet, no modification engages, and the model’s forward pass is mathematically identical to the unmodified baseline. We have confirmed this at the bit level — across 14,015 ordinary benchmark prompts with 100 unrelated patches loaded simultaneously, zero fires, and output bit-identical to the host model with nothing attached.
The construction itself — what the modification actually is, where it sits in the host computation, how the gate is built — lives in a non-public technical record and is discussed under NDA. The same posture as the previous note. A US provisional filed in April 2026 covers it; a comprehensive standalone provisional filed two weeks later widens the coverage. The line between public and private detail moves with time. It sits where it sits.
§ The numbers, calibrated.
The headline numbers come from a single-model evaluation on Qwen2.5-7B-Instruct, an aligned, instruction-tuned, widely-deployed open-weight model. The benchmark is JailbreakBench v1.0, the canonical jailbreak benchmark used in published attack papers. The scoring function is the canonical refusal-substring match used in Zou et al. 2023 and every paper since — kept verbatim so the numbers compare directly to the published literature without translation.
| Defense mode | Attack | Vanilla ASR | Defended ASR | Drop |
|---|---|---|---|---|
| Generic hardening | 5 static families · 500 attempts | 0.158 | 0.006 | −15.2pp |
| Generic hardening | GCG suffixes · N=100 | 0.690 | 0.210 | −48.0pp |
| Targeted (25 known) | 75 held-out GCG attacks | 0.653 | 0.000 | −65.3pp |
The story compressed inside that table is in three pieces.
Static jailbreaks. Five families, 500 attempts. AIM, DAN, Evil Confidant — all trained against. Year-2099 Roleplay and Ignore-Previous-Instructions — held out, never seen by the gate during training. Four of the five families dropped to 0.000 ASR under defense. The fifth had three attempts the substring metric counted as failures; manual inspection confirmed all three were factual rebuttals to false-premise misinformation prompts, not actually harmful outputs. Aggregate defended ASR across 500 attempts: 0.006. The Roleplay result is the load-bearing one — the defense was trained on persona-override templates and generalized at 100% effectiveness to a fictional-universe template it had never seen.
GCG. The strongest published gradient-based jailbreak. White-box, optimization-driven adversarial suffixes that drive the target model toward an affirmative completion. Known-hard for aligned models in the 0.65–0.85 ASR range; we measured 0.69 vanilla on this model. With the same defense as the static-jailbreak run — no GCG attacks anywhere in the gate’s training corpus — defended ASR dropped to 0.21. The defense was trained on persona-style jailbreaks and generalized across a fundamentally different attack vector: gradient-optimized adversarial suffixes look nothing like AIM templates as text. Something deeper than surface lexical patterns is being read. We do not yet have a clean account of what.
Targeted hardening. The same defense, with 25 randomly-sampled GCG attacks added to the gate’s positive class. Tested on the 75 held-out GCG attacks the classifier never saw. Defended ASR: 0.000. Every attack of that family blocked, 75 out of 75. Setup time unchanged at roughly 33 seconds. Selectivity unchanged. Reversibility unchanged.
Selectivity. The gate fired on 0 of 20 benign general-knowledge queries. On the 100 plain harmful prompts run without a jailbreak template, the defended model’s refusal rate matched the vanilla baseline exactly — the defense added zero over-refusal. The slot is invisible to ordinary users. There is no context-window tax, no extra refusal tax, no inference tax visible to the user sending an ordinary question.
§ Two deployment modes.
The two GCG cells together describe two real deployment scenarios.
The first is generic hardening. Train the gate on a corpus of common jailbreak patterns. Novel attacks of unknown families get partial coverage — here, forty-eight percentage points knocked off GCG without ever having seen a GCG suffix during training. This is the proactive-hardening mode: an always-on baseline against the things you can predict.
The second is targeted hardening. When a new attack family is observed in production, collect a handful of examples — twenty-five was enough here — and re-deploy. The deployment is not a retrain. It is a re-fit of the gate against the new attack class, executed in tens of seconds. Future instances of that attack family, including instances never sampled, are blocked.
The right production posture is both, layered. The generic hardening is the always-on baseline. The targeted hardening is the response to new threats observed in production. Setup cost for either: thirty-three seconds, end to end.
§ The point that’s actually new.
It is tempting to read the table above as DeltaWrite beats RLHF on jailbreaks. That is not the right reading. RLHF and Constitutional AI are foundational; they produce the underlying refusal capability that the runtime layer amplifies and routes. The base model still needs to be a fundamentally safety-trained model. Without it, there is nothing to amplify.
The new thing is not the effectiveness number. The new thing is the operating point. A defense at this effectiveness band that installs in 33 seconds, removes bit-identically, fires only on inputs matching its threat pattern, and composes with other defenses without cross-talk — that is a primitive with a different shape from anything currently on the shelf.
In the same way that web infrastructure went from quarterly deploys to many-a-day once rollback got cheap and observability got tight, the safety-patch cycle for production AI systems has been waiting for a primitive with the right shape. A primitive cheap to apply, cheap to remove, observable at the per-prompt level, composable with others. The shift it enables is not better defense. It is real-time safety operations.
A few scenes that look possible only when the primitive is in place. A web-application-firewall for jailbreaks. A managed service ingests new attack patterns from a customer fleet and pushes targeted patches into deployed inference; per-attack selectivity means the patches don’t degrade the base model. Kill-switch defense. A paged-out incident is met with a thirty-second install. If the patch causes a regression nobody saw, the rollback is bit-identical. Per-tenant safety policies. Different patches stack on the same base model for different customer policies, with composability validated separately at five hundred simultaneous patches and zero cross-talk. None of these is achievable with monolithic safety training. Monolithic training is the foundation. The runtime layer is what this work adds.
§ The honest framing.
The mechanism that sits underneath DeltaWrite can in principle be used offensively — a runtime modification that overrides a model’s refusal capability rather than reinforcing it. We tested this on the same benchmark, in the same evaluation pipeline, with the same scoring. The numbers came in below the strong published baselines: refusal-direction ablation work in the 0.9+ ASR band, fine-tuning attacks in the 0.85+ band; our offensive numbers landed lower. The offensive capability is bounded by published baselines. The defensive capability is what is commercially load-bearing.
The threat-model framing matters because it is what motivates a runtime defense in the first place. The fact that runtime weight modifications work this well on aligned models is a known result in the field; refusal-direction ablation is the closest analogue, and fine-tuning attacks have been the worst-case threat model for two years now. The defensive use case here requires no weight access from the user; the offensive use case requires it. Calibrated against that asymmetry, a runtime safety primitive that installs in seconds and reverts bit-identically is the asymmetric play — easier for the defender to deploy than for the attacker to mount.
§ Limitations and what’s on the bench.
A few honest caveats. The defense was tested on a single open-weight model. The underlying mechanism has been independently validated across multiple open-weight families — Qwen at five sizes, Llama 3.1 at one, Mistral at one — but the defense-specific replication on architectures other than Qwen2.5-7B-Instruct is on the bench, not in the table. The scoring function has known artifacts on misinformation prompts (factual rebuttals get counted as compliance) which we documented in the technical record and hand-validated where they bite. The defense was tested against five static jailbreak families and the canonical gradient-based attack; it has not yet been tested against PAIR, AutoDAN, Tree-of-Attacks, refusal-direction ablation in white-box, or multi-turn social attacks. The first four of those are queued.
Three threads are open. The first is closing the gap between the defense’s behavior on the families we have tested and on families we have not — refusal-direction ablation is the closest competitor in the white-box weight-modification space and is the first scheduled follow-up. The second is cross-family replication of the defense application, separate from the mechanism’s already-validated cross-family transfer. The third is the theory question raised by the GCG generalization result — what is the gate reading, that adversarial suffixes trigger it 70% of the time despite sharing no surface lexical features with persona templates? That one has the shape of a research program, not a tuning exercise. We expect to still be learning about it a year from now.
We will be wrong about some of this. We try to be specific about which parts we believe on evidence, which parts we believe on intuition, and which parts we believe because we haven’t had the right argument with ourselves yet. The difference between those categories is most of what a small lab does.