The shape of a bounded write.
A frozen language model that needs to learn something after deployment almost never needs a new distribution. It needs a small, reversible overlay that sits dormant on unrelated traffic. A note on the shape of that operating point — and on what an independent lab can say in public about a construction it would rather not hand to a fast follower.
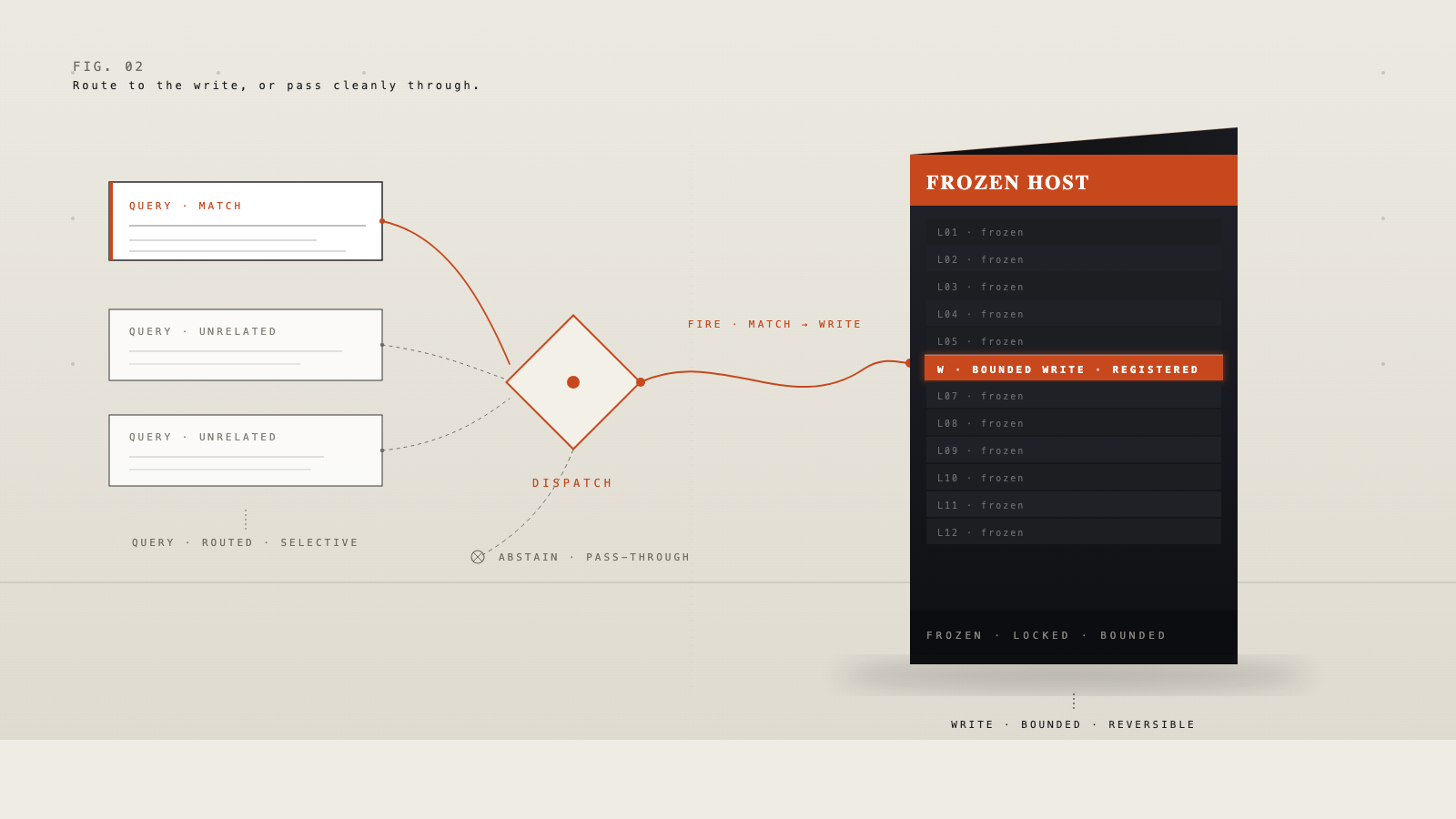
Most of the work at this lab over the last half year, and most of the arguments we have had with ourselves, have been about a surprisingly narrow thing. Not a better base model. Not a larger one. A way for a language model whose parameters are locked to acquire one more piece of knowledge or one more piece of behavior that it did not have five minutes ago — to keep it across sessions, to stop using it cleanly when we say stop, and to leave unrelated queries completely alone. In public the system we built around that goal is DeltaWrite. This note is about the shape of the problem we found at the bottom of it, and why we think the shape itself is the contribution worth talking about in the open.
§ The operating point nobody was serving.
The literature on adapting a pretrained model after the fact has converged on four answer-shapes. Prompting — keep the model frozen, write the new information into the context window on every call. Retrieval-augmented generation — keep the model frozen, store the new information in an external index, look it up at query time, inject the passages back into the prompt. Fine-tuning — resume training with a fresh objective and accept some amount of distributional disturbance in exchange. Adapter methods — train a small parameter family offline, attach it at inference, optionally swap per task.
Each of these is a reasonable answer to a slightly different question. None of them is a good answer to the one we cared about. The question we kept running into, in customer conversations and in our own tooling, was more specific than any of the four were designed for: can a deployed model acquire a bounded piece of knowledge or behavior — a single fact, a policy override, a terminology correction, a narrow behavioral mapping — that persists across prompts, can be removed cleanly, remains dormant on unrelated inputs, and lives alongside many other bounded items without any of them destructively interfering?
Prompting fails the persistence test and costs tokens on every call. Retrieval fails the persistence test in a different way and costs a lookup per query. Fine-tuning fails the cleanup test — it is a blunt distributional shift, not an overlay. Even parameter-efficient adapters, which people reach for as a middle ground, sit awkwardly here; they are trained objects, not registered ones, and they are not designed to stack as many narrow items. The operating point we wanted was in the empty quadrant.
What we have learned this year, first slowly and then quickly, is that the empty quadrant has a shape.
§ What a bounded write actually has to do.
The temptation, when you describe the gap above to someone for the first time, is to translate it back into one of the four answer-shapes the literature already has. Oh, you mean a small fine-tune. Or, you mean RAG with a cleaner index. Or, you mean one of the parameter editors. A bounded write is none of those, and the reason is in the joint requirements, not in any single one.
What has to be true, simultaneously, is this. Register a piece of knowledge or behavior at deployment time. Have it survive paraphrase — the same fact asked five different ways should reach the same outcome, not just the literal trigger string. Have it survive across processes — a session that shuts down and reloads should come back with the registered items intact. Have it stay dormant on every query that wasn’t aiming at it, including queries that look superficially similar but actually want the unmodified model’s answer. Have it be undoable on demand without rebuilding anything. And — the requirement that does the most damage to naive constructions — have it be one of many. A system that supports one bounded write is a parlor trick. A system that supports many is something else.
Each of those requirements, on its own, can be satisfied by something already on the shelf. The combination, satisfied at once, has resisted every off-the-shelf construction we put in front of it. That resistance is the substance of the operating point, and most of why the work took as long as it did.
§ What this essay won’t cover.
Some readers will reach this point hoping the next section is a recipe. It isn’t, deliberately. The construction we ended up with — what the registered object actually is, where it sits in the host computation, how the system behaves per query, how the per-host calibration works — lives in a non-public technical record and is discussed under NDA. The Public Technical Memo for GL-001 describes the system from the outside; the inventive details sit alongside it, not inside it.
We have wrestled, more than once, with how much to put in the open. The version of this essay six drafts ago had the architecture diagram in it. That version is not the one you’re reading because the right amount of public detail is the amount that lets a serious reader form an opinion about whether the system is real, and not the amount that lets a fast follower skip the months of work that produced it. The line moves with time. For the moment it sits where it sits.
§ The negative results are why to take the system seriously.
The headline numbers from our evaluation are in the technical memo, and they are what they are. The reason to trust them, we think, is not the headline numbers themselves but the negative results that sit next to them.
We can describe those negative results in shape if not in detail. Several constructions a reasonable person would try first, when reaching for “support many bounded writes at once,” fail in ways that are not subtle. They do not fail at the limit; they fail near zero, and they fail in ways that look correct on paper. Each of those failures took us weeks to characterize cleanly enough that we could rule the construction out rather than blame our implementation. Each is, in our view, an unforced error a competent team could make and lose two months to.
The discipline of putting the negative results next to the positive ones — in the same document, in the same font, at the same level of seriousness — is the part of the methodology we are most willing to talk about openly. It is also the part we think the rest of the field is going to be wrong about for a while. There is a publication-shape for this kind of work that reports the headline numbers and treats the failed constructions as ablations buried in an appendix. We think that has it backwards. The failed constructions are the result. The headline numbers are the calibration.
§ What sits in public, and what doesn’t.
DeltaWrite ships as a product. The public product page states the problem, places the system on the literature map at a level a serious reader can reason about, reports the evaluation honestly, and flags the negative results we have found. The reference implementation lives behind a working demo on the primary host that registers a sizable batch of facts into a live model, paraphrases them, saves the session to disk, exits the process, reloads in a new process, verifies the knowledge survives, forgets one item, and confirms nothing else was wiped.
What the public page deliberately withholds is the minimal recipe a competent team would need to reproduce the inventive core — the construction of the registered object, where it sits in the host computation, the calibration that adapts it across architecture families. That stays inside the lab and is discussed with integration partners under NDA. A provisional patent on the construction was filed in April 2026 to preserve the option; the technical record we share with partners is what makes the product evaluable in practice.
The split lets a reader who wants to know whether the system is real audit the public page, watch the demo, and form a grounded opinion without us having to choose between being legible and giving the construction away to the next person who would like to ship a competing product.
§ What’s on the bench.
Three threads are active, and each is a different kind of work. The first is closing the gap between the system’s best-case behavior and its behavior under realistic conditions, which is its own subproblem and not a tuning exercise. The second is a parallel research line that, if it works, would change which class of construction is preferable for this operating point; at the moment it is failing in informative ways. The third is theory — we have a system that works across multiple host families and we do not yet have a clean account of why the calibration looks the way it does across them. None of these threads is far enough along to write up. Each of them is a thing we expect to still be learning about a year from now.
There is a version of inference-time adaptation that is a product feature. There is another version of it that is a research program. DeltaWrite lives on the seam. The product version is what we are taking to customers. The research version is the reason we think the product version will still be interesting in eighteen months, when more teams have discovered the same operating point and many of them have walked into the same walls we did.
We will be wrong about some of this. We try to be specific about which parts we believe on evidence, which parts we believe on intuition, and which parts we believe because we haven’t had the right argument with ourselves yet. The difference between those categories is most of what a research lab does.